But where did ZKP’s come from, anyway?

ZKPs (Zero Knowledge Proofs) gained popularity during the crypto boom, but they have a rich history that dates back to the 1980’s. This article explores the origins and development of ZKP over the years. For a quick refresher on what ZKP’s are, please refer to my previous article on What the heck is a Zero-Knowledge Proof, anyway?
The basic premise of Zero Knowledge Proofs is that one party, the prover, can prove to another party, the verifier, that they have knowledge of a specific piece of information, without actually revealing what that information is. By doing this, the prover can demonstrate their knowledge of a particular fact or piece of data, without revealing any additional information.
Now, let’s dive in!
Origin Of ZKPs (1980’s)
ZKPs gained traction during the crypto boom because they allow for trustless and anonymous exchange between two parties, but the concept in itself is not new. The history of ZKPs can actually be traced back to the late 1980s, when Shafi Goldwasser, Silvio Micali, and Charles Rackoff introduced the concept in a paper titled “The Knowledge Complexity of Interactive Proof-Systems”
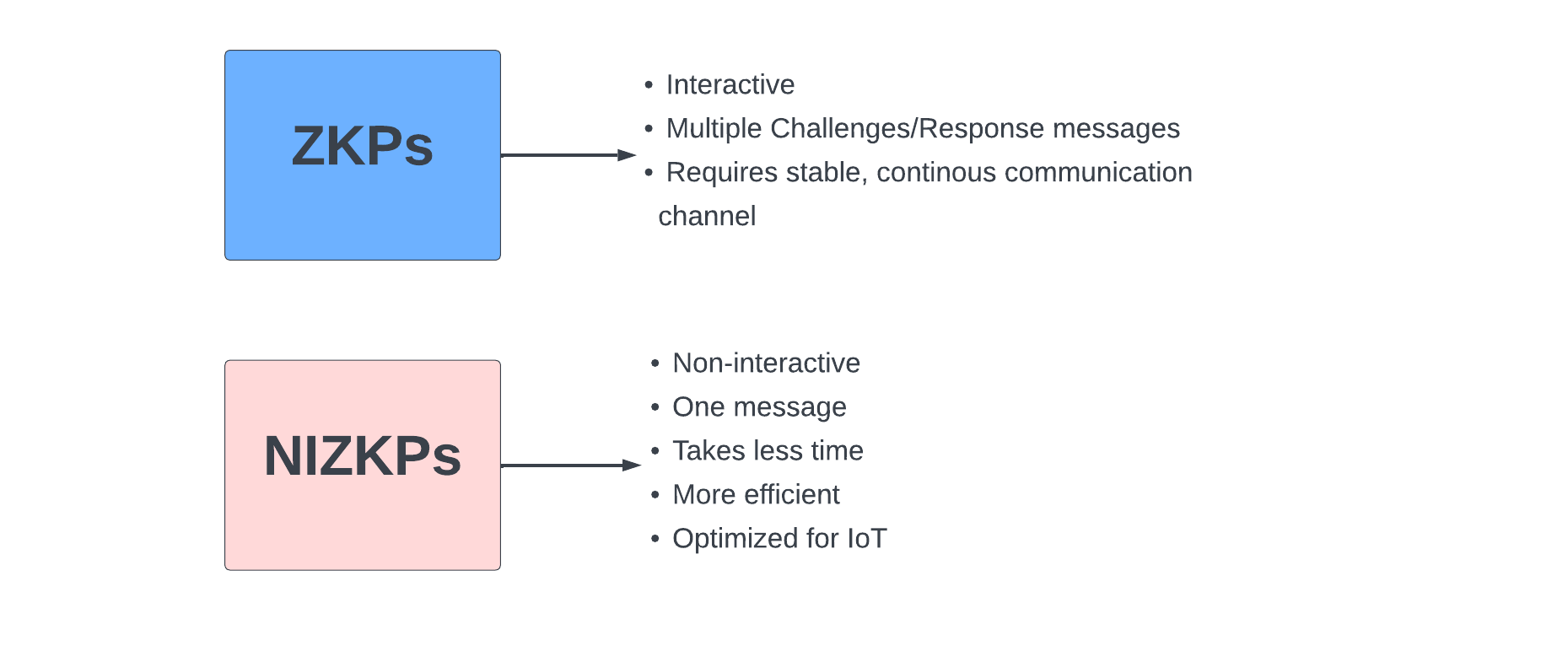
The original concept as described by the authors involved something called “Interactive protocols” where the prover and verifier would communicate back and forth (interact over and over) to convince the verifier that the prover knew the correct information. This approach, although a breakthrough of its own, proved to be time-consuming and resource-intensive, particularly when large volumes of data were involved. For Zero knowledge proofs to be scalable, they need to be non-interactive.
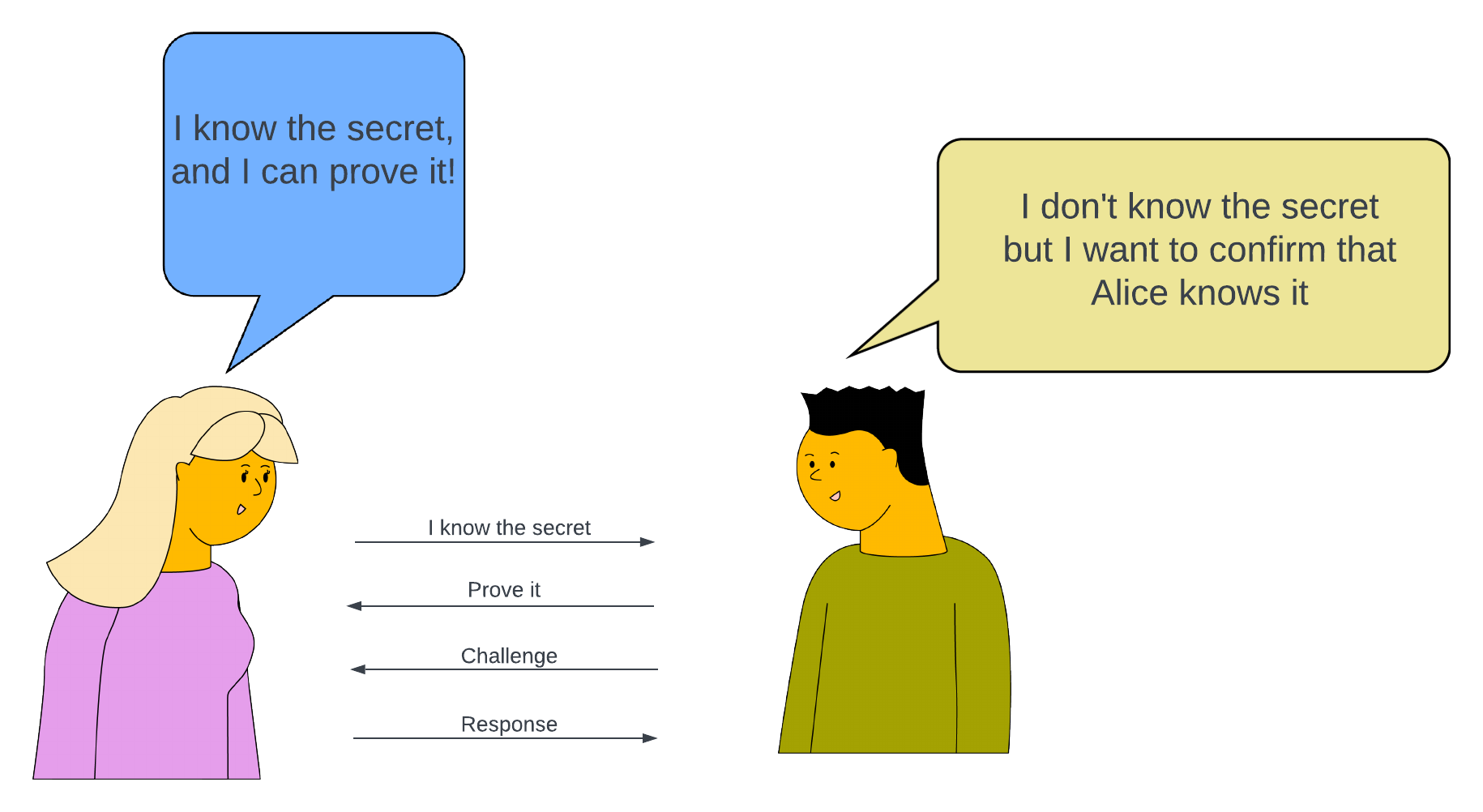
In 1986, Fiat and Shamir invented the Fiat-Shamir heuristic (a technique for taking an interactive proof of knowledge and creating a digital signature based on it) and successfully changed the interactive zero-knowledge proof to non-interactive zero knowledge proof. This now made ZKP’s non-interactive, and laid the foundation for widespread, scalable use of ZKP.
Enter zkSNARKs
Fast forward a couple of years, and the next big push to ZKPs happened in 2011, where a paper called "From Extractable Collision Resistance to SNARKs and Back Again" was published at the International Symposium on Theory of Cryptography by Nir Bitansky, Ran Canetti, and Alessandro Chiesa.

This paper showed that we can use something called Extractable Collision Resistance (ECR) hash function to create SNARKS (succinct non-interactive arguments of knowledge). SNARKS are basically ZKP that are “succinct” meaning they are small in size and can be verified in a matter of seconds.
From here on, the progress of ZKP accelerated, and led to the creation of Pinocchio in 2013.
Pinocchio which was one of the first proof-of-concept implementations of a of the zero-knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARK) proof system and was considered a breakthrough in the field. It was in use until a couple of years ago, but was then replaced by newer and more efficient versions of zk-SNARKs.
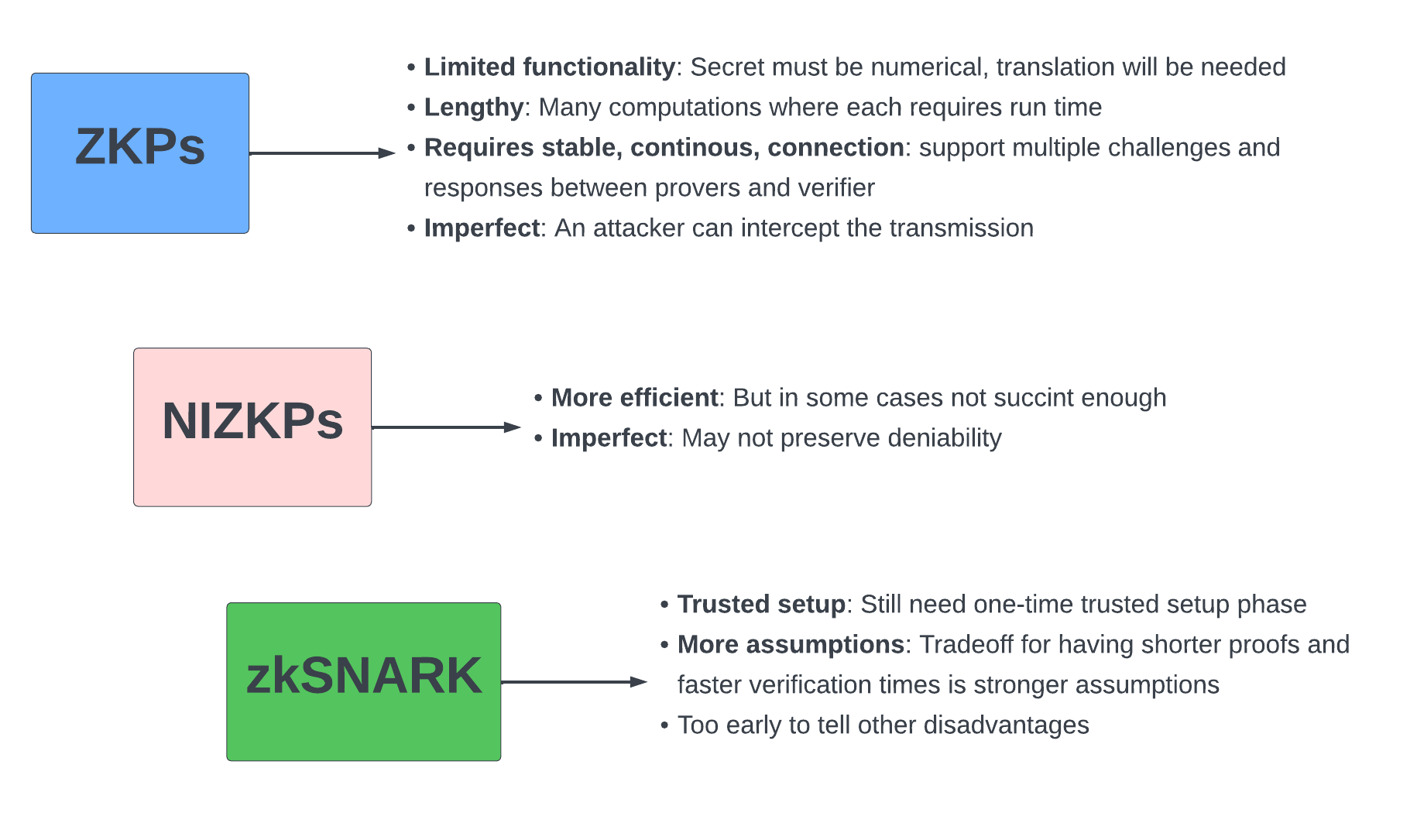
Two major downsides of zkSNARKS at the time were:
- Requirement of a trusted setup
zkSNARKs require a "trusted setup" between a prover and verifier. This setup phase is used to create a set of initial parameters that are then used to generate and verify the zk proofs.
Generating these parameters requires some secret information. A group of people usually generates these secrets and then uses the secrets to generate the parameters. Once the parameters are generated, the secrets are discarded. However, because the secret inputs need to be generated by a set of people, it requires us to "trust" these people.
In a blockchain setting, we want to minimise trust so that is why "trusted setups" are generally not favoured.
zk-SNARK proofs were dependent on an initial “trusted setup” between a prover and verifier, meaning that a set of public parameters is required to construct zero-knowledge proofs and, thus, private transactions. These parameters are almost like the rules of the game, they are encoded into the protocol and are one of the necessary factors in proving a transaction was valid. This creates a potential centralization issue because the parameters are often formulated by a very small group.

- Not post-quantum secure
zkSNARKS are not post-quantum secure, because they rely on public key cryptography. Public key cryptography relies on the hardness of solving the discrete log problem over certain groups of numbers. But with the creation of quantum computers, public key cryptography is at risk because factoring large numbers into primes would be feasible by computers, which means solving the discrete log problem isn’t hard anymore.
The industry was hard at work trying to build protocols that solve these two problems.
2016-2018 - Making SNARKs Practical
Next came Groth. Groth, introduced in 2016 was one of the first protocols that made Zsnarks efficient and extremely practical to use. It was such a huge breakthrough and got immediate adoption. In fact, it is still being used in a lot of protocols today and has a lot of tooling built around it, because of its performance and simplicity.
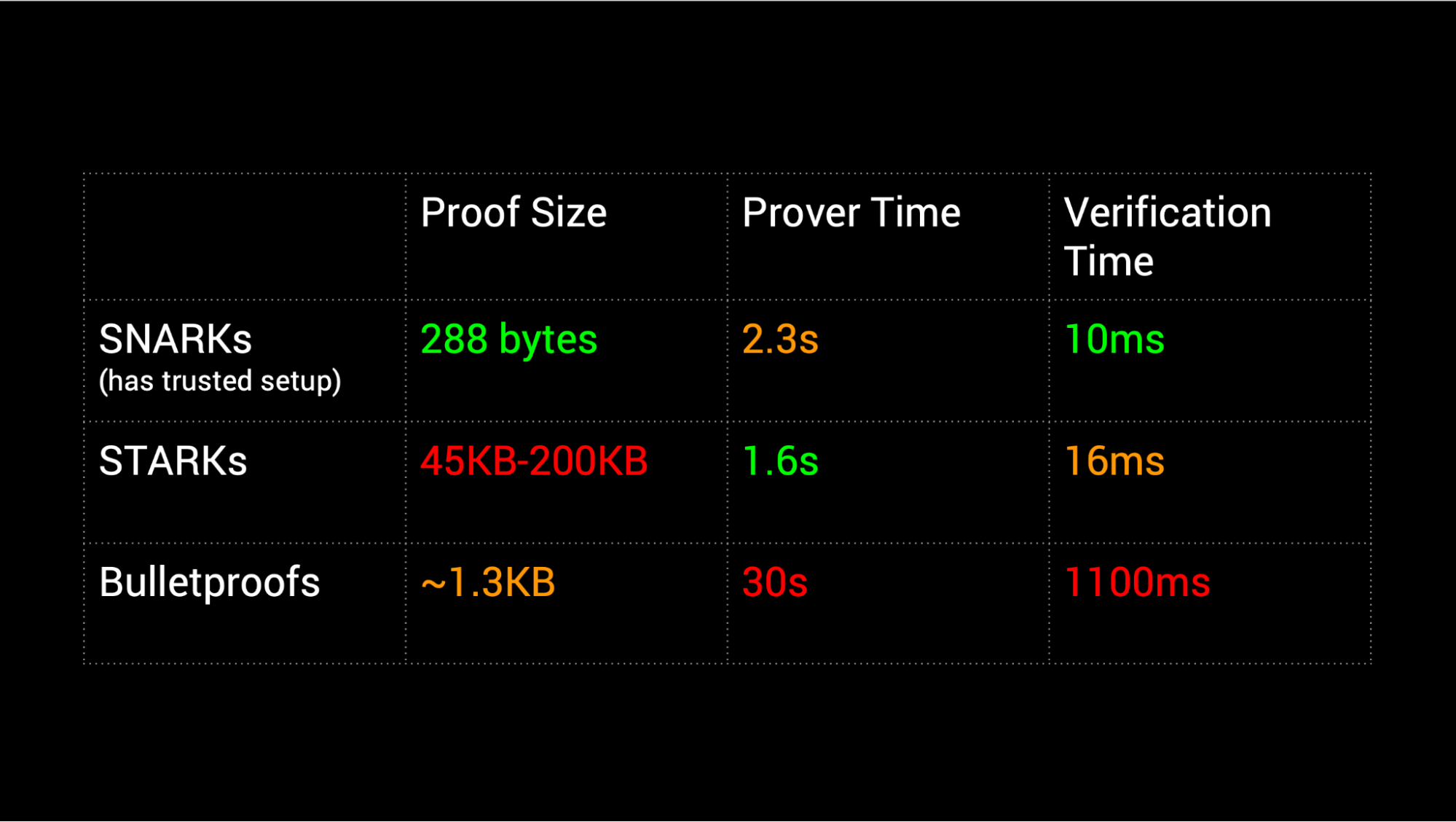
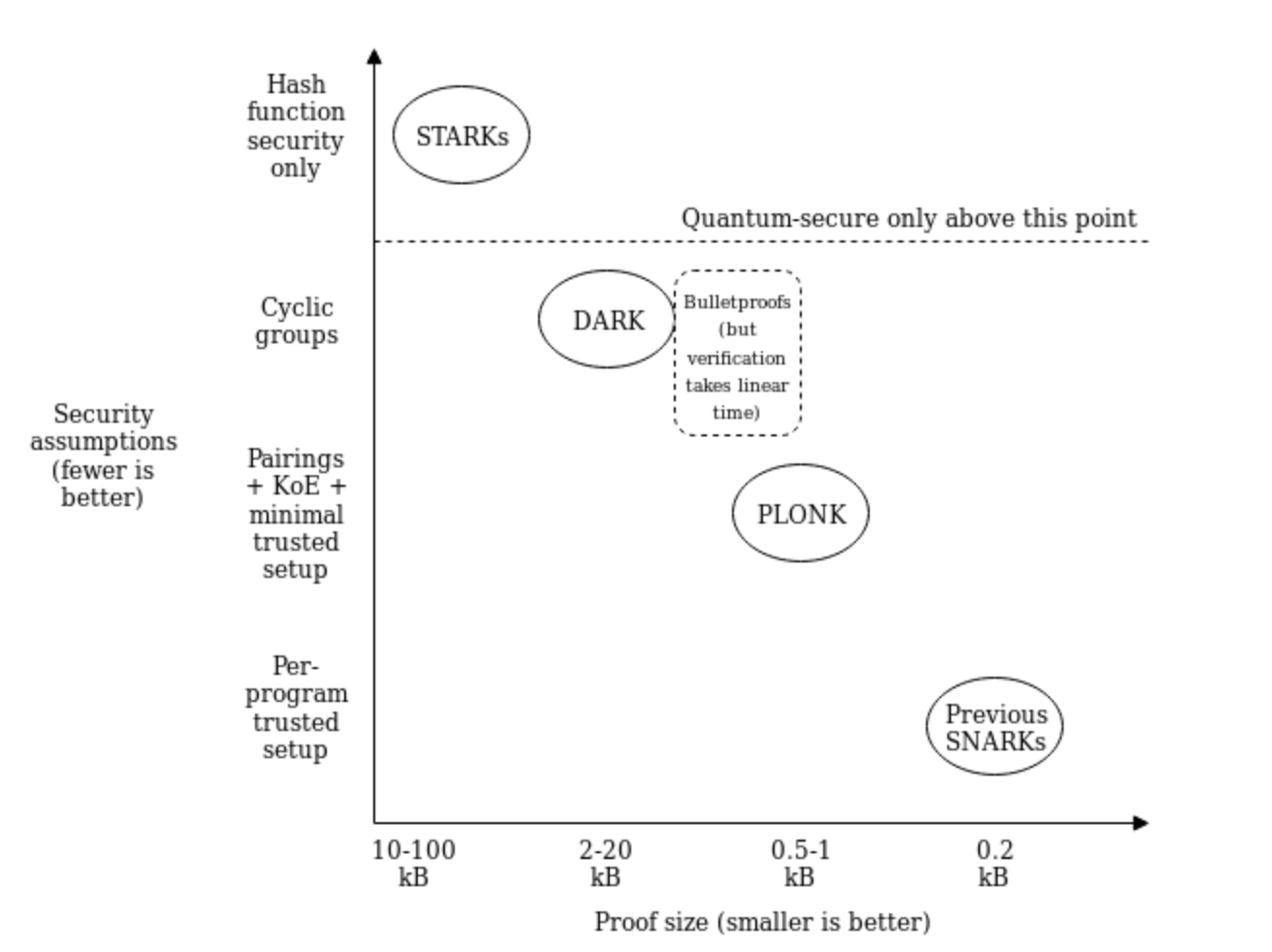
The next major milestone in the industry was the introduction of Bulletproofs in 2017. I remember bulletproofs being the hype during 2017. Bulletproofs are short, non-interactive zero-knowledge proofs that can prove that a certain encrypted value lies within a given “range” without disclosing any information about the number (eg. I can prove to you that the transaction value is within a certain range without revealing the amount). These “range proofs” can be aggregated into a single, short proof. The reason bulletproofs became so popular is because they made confidential transactions on Bitcoin not only possible, but efficient. The biggests differentiator of bulletproofs was that it required no trusted setup. This is extremely important in the blockchain industry because we’re focused on building trustless networks, and as you can imagine, the industry lapped up bulletproofs fast.
2018 - STARKS
In 2018, STARKS (short for Zero-Knowledge Scalable Transparent ARguments of Knowledge) made a big splash in the industry by mitigating the two downsides of zkSNARKS:
-
STARKS are “post quantum secure” meaning that they relied on hash functions instead of elliptic curves for the proving mechanism.
-
STARKS do not require a trusted setup. Instead, zk-STARKSs use publicly verifiable sources of randomness as the initial parameters.
The biggest drawback of zkSTARKS was that they had a large proof size. This made it not ideal for blockchains because storage on-chain costs money. However, STARKS pushed SNARKS to step up and move away from trusted setups.

2019 - The year of the SNARKS
2019 was a huge year for zkSNARKS, with 3 major innovations in the field:
The big contribution that sonic made was supporting “universal” and continuously upgradeable reference strings. This means that you didn’t need to do a trusted setup to generate the initial parameters for every program. Instead, you do the trusted setup once and use the same parameters for all your programs. While this doesn’t completely mitigate the downsides of a trusted setup, it definitely made it better.
Sonic also had a constant proof size (which is good because the proof size didn’t increase with the complexity of the program) and introduced batch verification which reduced verification time. However, when you didn’t batch, the verification time was notoriously high.
Marlin was a significantly improved version of Sonic, and reduced proof time 10x. It also offered faster verification without batching, and improved verification time by 3x.
PLONK, short for “Permutations over Lagrange-bases for Oecumenical Non Interactive Arguments of Knowledge '' is another improved version of SONIC which, among other things, reduced proof time by 5x. The big innovation here was that PLONK allowed for custom gates other than the usual addition/multiplication, which meant that you can build zk proofs for much more complex programs.
Both PlonK and Marlin replaced the circuit-specific trusted setup in Groth16 with a universal setup. With the introduction of PLONK, the crypto community also realized that they could even build “zkEVMs”, which would allow us to take any smart contract code on Ethereum and convert it into zero-knowledge proofs. For those interested to read more, here’s a great article by Vitalik explaining the maths behind it.
That marked the end of a very eventful year for Zero Knowledge Proofs, but it was only the beginning!
2020 - Present
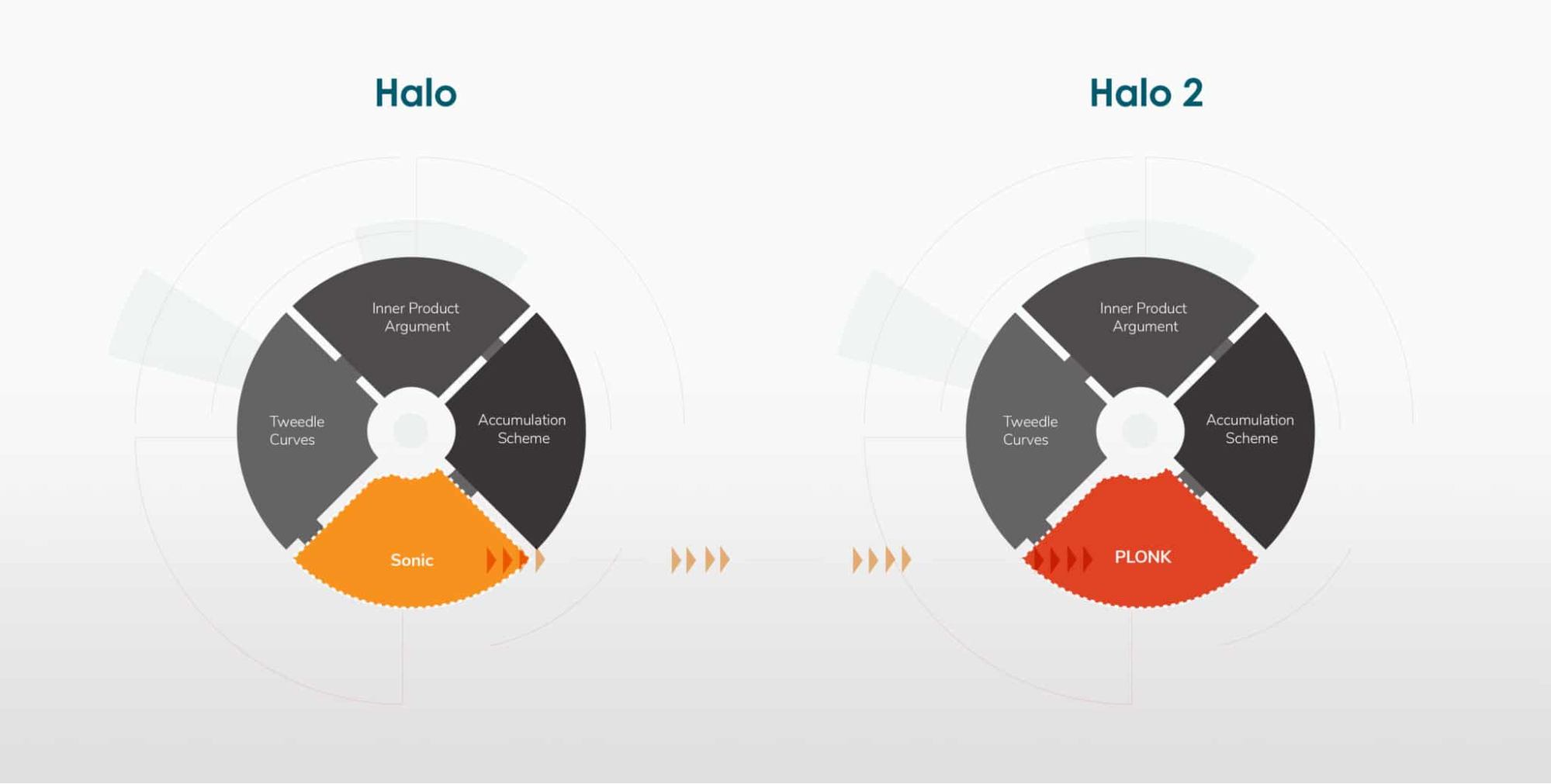
In 2020, the Zcash team introduced HALO 2 (a successor to HALO) which combined the best of both PLONK and Bulletproofs, which then allowed for fast verification without trusted setups.
Fast forward to 2022, and we started to see an acceleration in new protocol development again.
HYPERPLONK, a zk-proof system with a fully linear time prover and support for high-degree and lookup custom gates, was introduced in 2022. It was an attempt to improve upon the flexibility of PLONK, improve its speed and provide further benefits.
While pretty robust on its own, PLONK had certain limitations, especially when proving large statements or trying to use highly parallel hardware. These limitations are especially important when proving large and complex statements such as rollups and zkEVMs. HyperPlonk aims to solve this.
Most recently, Plonky2, released by Polygon in January 2022 is the latest in the world of ZKP. It is a recursive SNARK that is 100x faster than existing alternatives. It combines PLONK and FRI for the best of STARKs (ie. fast proofs and no trusted setup), and the best of SNARKs (ie. support for recursion and low verification cost on Ethereum).
And that brings us to today. This is how the ZKP Landscape looks today:
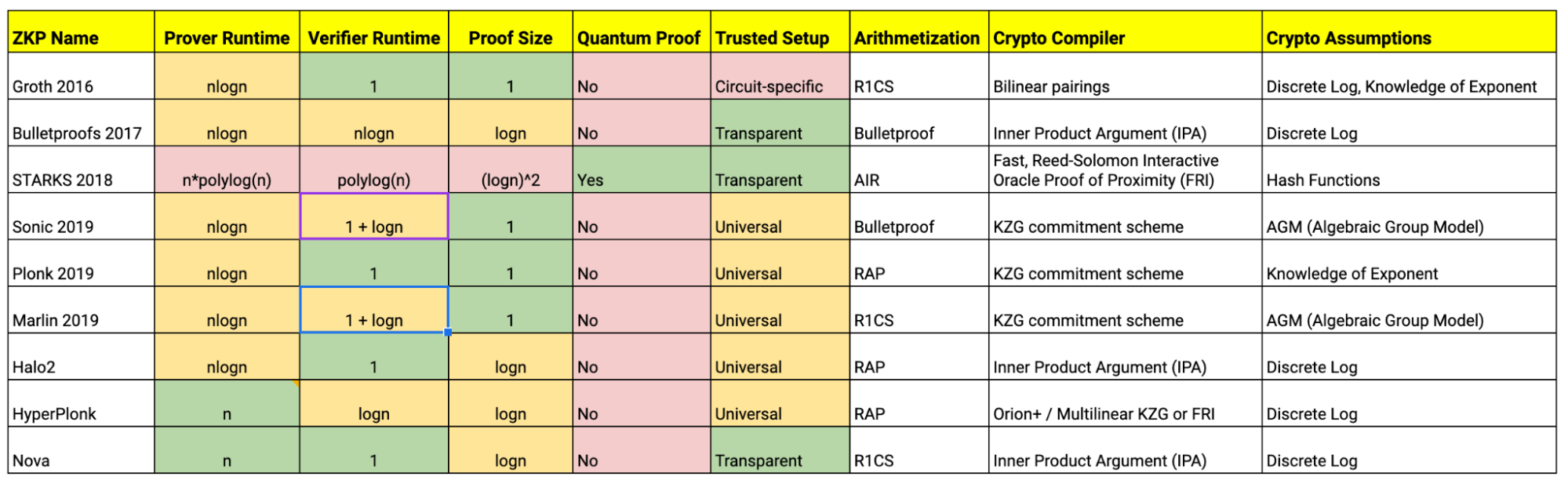
While there is no “protocol” which is considered to be the best, knowing about all these protocols, their benefits and their limitations helps us pick the best one for our specific use case and setup. My team has collected information on all of the protocols that I covered today, and summarised them for you here:
ZKPs have a long and rich history, with each protocol pushing the envelope, improving the speed and expanding the limits of this technology. We’ve certainly come a long way from the first iteration which required the prover and verifier to go back and forth to exchange information, haven’t we? 🙂
In my opinion, we’re just getting started. What do you think will be the next big innovation in the ZKP space?